
Hey there! I receive pretty frequently questions around what storaget to use in Azure Red Hat Openshift (ARO), hence I decided to write this post.
Using storage in Kubernetes in general and Openshift in particular has many nuances. I/O bottlenecks can quickly become an issue impacting the cluster integrity, the application performance, or both. This article will help you understand the storage components in your cluster that can affect application performance, as well as how to select the best storage option for workloads running in your Azure Red Hat Openshift cluster that need permanent storage, such as databases or logging subsystems.
VMs and disks I/O limits
The first and foremost task of cluster administrators is to size cluster nodes appropriately (both masters and workers). This sizing typically involves CPU and memory, but disk performance should be considered too. Openshift nodes will have certain performance limits when accessing their disks in terms of I/O (Input/Output) operations per second (IOPS) and throughput (Megabytes per second or MB/s). If a node’s disk does not offer enough performance, that Openshift node can potentially go into an undesirable state and impact the overall cluster scalability. Providing enough I/O performance for your Openshift nodes is the first step towards a healthy cluster.
Openshift nodes
In Azure Red Hat Openshift you want to make sure that the virtual machines where the master and worker nodes are installed have enough disk performance, and they are not hitting any I/O bottlenecks. In Azure virtual machines there are two types of I/O limits that might be limiting the I/O performance:
- The VM I/O limit, determined by the VM family and VM size
- The disk I/O limit: determined by the disk size
Per default, ARO worker nodes are created with 128-GB disks for the operating system, which would correspond to the disk size “P10” according to the table in Azure Virtual Machine Disks Types. Additionally, this table tells you that the disk performance is going to be limited at 500 IOPS (with the possibility of bursting up to 3,500 IOPS) and 100 MB/s.
Certain scenarios, such as very dynamic clusters with frequent Openshift API operations, will trigger a high number of operations in the Openshift node that could overwhelm the disk. Hence, when creating a cluster you can decide to provision the nodes with a larger disk, that will result in a higher disk performance (for example using the --worker-vm-disk-size-gb flag if you are using the Azure CLI to create the cluster).
Note
The OS disk size can only be defined at cluster creation time, you will have to recreate your cluster if you decide to change this later.
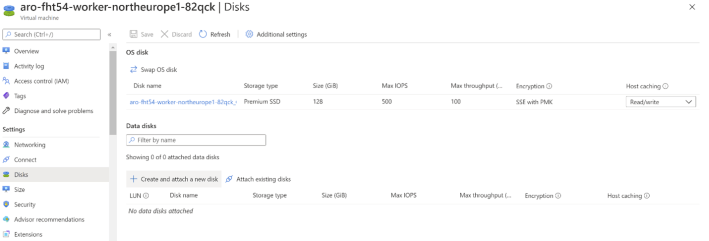
However, increasing the size of the disk will only increase the I/O performance of the Openshift node as far as the actual limits of the virtual machine allows. As described in ARO Support Policies, there are multiple VM sizes you can choose from for your Openshift masters and workers. If we take for example the smallest DSv3 size supported (Standard_D4s_v3), in the documentation for this VM size Dv3 and DSv3 VM Series you can see that the D4s_v3 will give you a cached I/O performance of 8,000 IOPS and 64 MB/s (see in the screenshot above how read/write caching is enabled for worker node OS disks). No matter how large the disks in the VM are, they will never be able to generate more I/O than the VM limit. Taking a larger VM size would push those limits up: for example, a D8s_v3 can have a cached performance of 16,000 IOPS and 128 MB/s.
Consequently, make sure to monitor the disk performance (IOPS and throughput) of the OS disk in your worker nodes using the Metrics blade of the Virtual Machine. If the VMSS cluster is running too close to the limit, you might want to redeploy the ARO cluster using a larger OS size.
Master nodes are created with a larger disk size (1,024 GB) as the next figure shows, to make sure that they get all the performance they need (master node failures are usually more impactful than worker node failures).
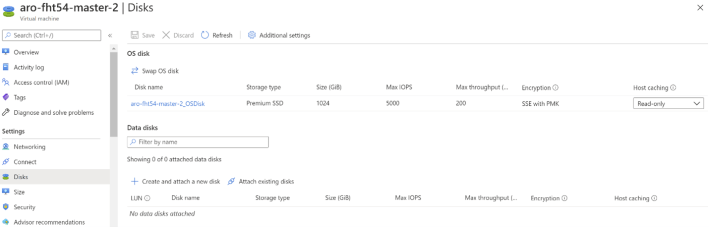
Another difference in the I/O configuration of masters and workers is in the caching mode for the OS disk. As you can see in the previous screenshots, master node disks are configured with read-only caching. This is done so to prevent data corruption in case a problem happened before fully completing a write operation in the Openshift control plane, which could potentially render the cluster unusable. In this case the ARO configuration favors stability at the cost of a slightly higher latency for write operations. The worker OS disks are configured for read/write caching, which will give a higher performance by using the ephemeral SSD local to each Azure host as a cache for both reads and writes.
Disk-based persistent volumes
I/O performance is not only important for the correct operation of the Openshift nodes in a cluster, but certain workloads will require to store state in persistent volumes. For example, some applications might log into a common log repository, and databases will persist information to some storage platform. Selecting the right type of persistent storage volumes for each workload is critical to guarantee the correct operation of your applications.
One of the first choices for application persistent volumes is Azure Disks. The discussion about the OS disks in Openshift nodes is also relevant for disks used as persistent volumes, since these are connected to the Virtual Machine as data disks before they can be attached to a pod. Note that the documentation for the Azure VM sizes describes as well how many data disks (additional to the OS disk) can be connected to an Azure VM. For example, as documented in Dv3 and DSv3 VM Series, you can only attach 8 data disks to a Standard_D4s_v3, while you can attach 16 disks to a Standard_D8s_v3 VM. Hence the size of your worker nodes is going to determine how many pods requiring disk-based persistent volumes are going to be supported in each node.
Another aspect to consider is that the I/O generated by the pods with disk-based persistent volumes is going to count against the overall I/O maximum of the VM (IOPS and MB/s). Hence please consider sizing the VM accordingly so that it can cope with load on the both OS disks and the data disks required for persistent volumes.
Azure disks and Availability Zones
One important attribute of disks in Azure Red Hat Openshift is the fact that both disks and nodes are deployed in Availability Zones to maximize uptime. Availability Zones guarantee that if there is a problem in one of the data centers in an Azure region impacting part of the Openshift cluster, that problem is not going to propagate to the rest of nodes in the cluster.
Virtual machines can only be connected to disks in the same Availability Zone, hence restarting a pod in a different Availability Zone will result in a disk access failure. For example, consider pod1 running in node1 in AZ1 with a disk-based persistent volume. If pod1 should restart for any reason it could only restart in a different node in the same AZ1, otherwise it would not be able to access its own disk. As a consequence, if the applications in the cluster use disk-based persistent volumes you should consider using Openshift MachineSets dedicated to an AZ with at least two nodes per machine set, and pinning down pods to machine sets using Kubernetes taints and tolerations.
Another option you should consider when using disk-based persistent volumes is WaitForFirstConsumer. This option makes sure to create the Azure Disk in the same Availability Zone where the consumer pod will be scheduled. You can refer to Kubernetes Volume Binding Mode for more details on this.
Disk replication
Knowing how data in Azure disks is protected against data loss is very important to understand the availability and durability of application data in Azure Red Hat Openshift. As described in Managed Disks Overview, Azure managed disks offer 99.999% availability by providing you with three replicas of your data, allowing for high durability.
See later in this document backup strategies for persistent volumes.
Storage classes and volumes
Storage classes are a Kubernetes concept that is used so that Kubernetes can dynamically create the storage required by applications. The configuration of each storage class will determine the properties of the storage resource created in Azure, such as its geo-replication settings or its performance tier. Azure Red Hat Openshift is created with a default storage class that will provision Azure Premium Disks when used to create a Persistent Volume Claim:
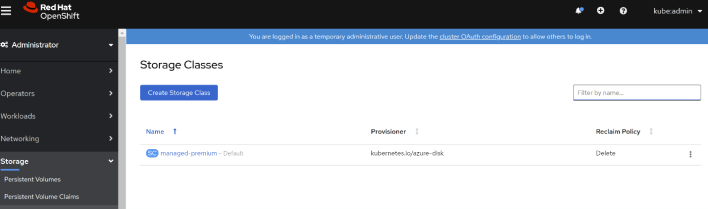
You can see the detailed configuration of this storage class for Azure Premium Disks if you look at the YAML definition:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: managed-premium
annotations:
storageclass.kubernetes.io/is-default-class: 'true'
ownerReferences:
- apiVersion: v1
kind: clusteroperator
name: storage
provisioner: kubernetes.io/azure-disk
parameters:
kind: Managed
storageaccounttype: Premium_LRS
reclaimPolicy: Delete
allowVolumeExpansion: true
volumeBindingMode: WaitForFirstConsumer
Azure Managed Disks are great for many use cases, but for others you might want some different type of storage: first, as we discussed Azure Disks are located to specific Availability Zones, so they cannot be mounted from every node in the cluster. Secondly, they are what Kubernetes describes as a ReadWriteOnce storage type, meaning that they can only be mounted from one pod at any given point in time. If you need a ReadWriteMany volume that can be mounted by multiple pods simultaneously there are different options you can choose from, what we will cover in the next sections.
Azure Files Storage Class
Azure Files is a file-based, ReadWriteMany option very useful for use cases such as file shares that do not require an extremely high performance in terms of IOPS and throughput.
You can create a storage class for Azure Files using the Openshift console:

The previous wizard would create this storage class:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: myazfiles
provisioner: kubernetes.io/azure-file
parameters:
skuName: Standard_LRS
reclaimPolicy: Retain
volumeBindingMode: Immediate
You can find more info about the parameters that the storage class for Azure Files accepts in the Kubernetes documentation for Storage Classes.
There is an important attribute with Azure Files, which is the SKU name. Azure Files offers different performance levels, as documented in Azure Files Scales Targets:
- Azure Files Standard: there is a performance difference depending if you have enabled a feature in your Azure Files share known as Large File Shares (see Enable Large File Shares)
- Non “large file shares”: 1,000 IOPS, 60 MiB/s
- “Large file shares”: 10,000 IOPS, 300 MiB/s
- Azure Files Premium is completely different, because performance is a linear dependency of the share size. Which means that smaller sizes will have a poor performance (even worse than Azure Files Standard), but larger shares will have a very good performance. The formula (out of the previously mentioned article) for the maximum number of IOPS and bandwidth is:
- IOPS: 1 IOPS/GB (bursts of 3 IOPS/GB) up to a maximum of 100,000 IOPS
- Egress throughput: 60 MiB/s + 0.06 * provisioned GiB, up to a maximum of 6,204 MiB/s
- Ingress throughput: 40 MiB/s + 0.04 * provisioned GiB, up to a maximum of 4,136 MiB/s
This means that if you only need say only 10 GB, Azure Files Standard with Large File Shares support will give you better performance than Azure Files Premium.
Azure Disks
Similarly, you can create other storage classes that create Azure Disks using the Openshift console:
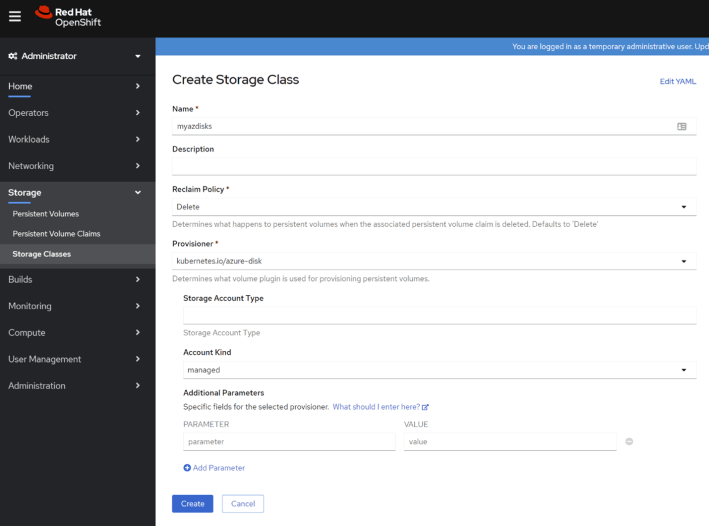
Here you can see an example of a storage class for Azure Disks:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: myazdisks
provisioner: kubernetes.io/azure-disk
parameters:
kind: managed
reclaimPolicy: Delete
volumeBindingMode: Immediate
You can find additional info about the azure-disk provisioner in Kubernetes documentation for Storage Classes
NFS
NFS (Network File System) is slightly different from Azure Files and Azure Disks, because you can use it without a provisioner (meaning that Kubernetes will not control the creation/deletion of the NFS shares in Azure as it does with Azure Files and Azure Disks). Instead, the pod will mount directly the volume in the NFS share. There are a number of choices for NFS in Azure:
- Azure Files shares can be exposed over NFS as well (see How to Create NFS Shares.
- Azure Netapp Files offer NFS support( see Create Azure Netapp Files volume.
- You can build an NFS cluster with Virtual Machines on Azure (see for example this High Availability Guide for SUSE and NFS
This example in the Azure Kubernetes Service documentation shows how to create a persistent volume backed by an NFS share (in the example an Azure NetApp Files volume).
The performance of an Azure NetApp Files share depends on its size and on the chosen Azure Netapp tier:
- Ultra: 128 MiB/s of throughput per 1 TiB of volume quota assigned.
- Premium: 64 MiB/s of throughput per 1 TiB of volume quota assigned.
- Standard: 16 MiB/s of throughput per 1 TiB of volume quota assigned.
Something to note is that the minimum capacity pool that you can provision with Azure Netapp Files is 4 TB, which makes it better suited for large shares.
Azure Netapp Files and Trident
NetApp has launched the project Trident (https://netapp-trident.readthedocs.io/), an orchestrator that allows Kubernetes to control the lifecycle of shares on Netapp devices. It supports Netapp technology deployed in Azure (Azure Netapp Files) as well as on-premises and other public clouds. You would consider Trident if instead of having an existing volume where you want your application to log, you want your applications to dynamically create (and optionally delete) those volumes for you, for example for multi-tenant environments where the instantiation of a new tenant should create a new share volume.
Describing Trident is outside of the scope of this document.
Emptydir
A popular choice for testing storage volumes is emptydir, which mounts a directory of the node file system into a pod. Be careful with this technology, since if you use emptydir to let the pod write into the node’s OS disk and it reaches the disk or the node I/O limits, it will impair the correct functioning of the node. Hence emptydir volumes should only be used when the additional I/O load for the node is going to be negligible, for example to store configuration data that the application will read at startup.
Example performance calculation
In this example we are going to use the information in the previous sections to demonstrate how you would choose and size the persistent storage for your application. Since performance is typically the area which is most difficult to size, you want to start with performance requirements and then calculate the required capacity for each storage platform. In our example, the performance requirements have been identified as follows:
- 5,000 IOPS
- 320 MB/s write bandwidth (block size of 64KB)
Now we can evaluate the minimum size that we need for each storage platform:
- Disk-based persistent volumes: A P30 (1 TiB) would satisfy the IOPS requirement, but not the bandwidth one. Two striped P30 disks would provide a combined performance of 10K IOPS and 400 MB/s. Note that your Openshift worker nodes need to be able to cope with the I/O. This depends as well on whether the disks are mounted with caching enabled or not, but assuming they are not a possible candidate for the Openshift worker nodes might be the Standard_D16s_v3 (uncached 25,600 IOPS and 384 MB/s).
- Virtual machine with NFS server: the benefit of this method is that you don’t necessarily need to change your Openshift nodes. You need to build an NFS cluster on VMs with data disks satisfying the I/O requirement (like the proposed striped P30 disks). The Virtual Machine must be able to cope with the bandwidth, so it could be a Standard_D16v3 too.
- Azure Files Standard: Azure Files Standard is not an option, since the maximum per share is 300 MB/s
- Azure Files Premium: 5 TB would result in the required 5K IOPS. However, in order to achieve the write bandwidth objective we need to increase up to 7 TB (40 + 0.04 * 7000 = 320 MB/s)
- Azure Netapp Files: we could start with the minimum 4TB capacity pool and the Ultra tier (4 x 128 = 512 MB/s). A more cost-efficient alternative would be provisioning 5 TB in the Standard tier (5 x 64 = 320 MB/s). This is closer to the requirements, plus allows for scaling up the tier from Standard to Premium if required.
As you can see, there are multiple solutions that meet the initial requirements. Which one is the best for each scenario will depend on factors such as cost, added operational complexity or any previous experience with each technology.
Openshift Container Storage
Openshift Container Storage is a software-defined storage functionality that Openshift will support. As indicated in Planning Openshift Container Storage Deployment on Microsoft Azure, this feature is still in preview for Openshift 4.4, so it is out of the scope of this document.
Backup
If your application state is stored outside of the Openshift cluster in Azure services such as Azure Database for MySQL, Azure Database for Postgres or Azure CosmosDB, your data will be backed up by those services with their built-in functionality. However, if you are storing your data in volumes mounted by your pods, you might want to backup to prevent data loss. Some storage options will support native backup functionality:
- Azure Files shares can be backed up by Azure Backup for Azure Files
- You can back up Azure Netapp Files using the rich Netapp software ecosystem
- If using an NFS cluster on VMs, the VMs and their disks can be backed up using Azure Backup
Today there is not an easy way of backing up Azure Disks, since this technology does not support out-of-the-box replication to other Azure regions (GRS, RA-GRS) in order to prevent data corruption. Replicating a block device can only be performed safely if the Operating System and the applications have been quiesced during the snapshot operation.
The better alternative you should consider to protect data stored in disks is having the application itself doing the replication. For example, most databases can replicate data to other systems in the same or different geographical regions both synchronously and asynchronously, and guaranteeing data integrity.
There are other third-party options that help not only with the backup of persistent volumes, but with the backup of the cluster configuration itself as well. Here a few of them:
However, regarding the cluster configuration itself, Microsoft recommendation is documenting and scripting cluster deployment in a Continuous Integration / Continuous Deployment pipeline, so that not only you can recover from disasters quickly, but you can create test environments with a configuration identical to production with little effort.
Secrets stores
If your workloads leverage secrets such as database connection strings, digital certificates or passwords, the native Openshift option is to store those as Kubernetes secrets. An alternative pattern is to keep that sensitive information in specialized devices equipped with hardware and software security features purpose-built for secret management. The advantage of such a design is a higher security protecting your secrets, plus a cleaner separation of concerns between cluster operators, application developers and security custodians. From those secure stores, secrets can then be injected into pods via storage volumes.
One example of this integration is the Secrets Store CSI Driver for Azure Key Vault. This driver allows storing your application secrets such as SQL connection strings or encryption keys in Azure Key Vault, an HSM-based (Hardware Security Module) enterprise grade secrets store certified with standards such as FIPS 140-2 level-2.
Note
This technology used to be implemented with Kubernetes FlexVolumes, but the community has transitioned to the more modern Container Storage Interface (CSI).
Persistent Volume use case examples
After covering the different implications of choosing one technology or the other for data storage in Openshift, we can cover some typical use cases:
- Databases running on pods: the database software will typically offer shared-nothing, high-availability solutions that are not depending on shared storage, so ReadWriteOnce persistent volumes like disks are a viable option here.
- Shared-nothing clustered software: certain software solutions (such as Zookeper) do not require common access to shared storage. Here again disk-based persistent volumes will offer a good performance.
- Shared access to repositories with many (thousands) files and folders: Azure Netapp Files does a great job at large file shares enumeration, even with many files and folders
- Application data initialization: some applications will require downloading some data before starting their operation, such as configuration files or the latest sales data. This is only done periodically after batch jobs generate that data, so performance requirements are not too high. Azure Files is a cost-effective solution for this scenario
- Shared logging: for low-bandwidth logging Azure Files would be a good fit. If higher performance is required because of a large logging volume, Azure Netapp Files would be a better candidate.
I hope this post helped you to understand the different storage options available in Azure for Openshift, and when to choose which. Please do not hesitate to let me know in the comments if I forgot to add anything.

Super helpful info, thanks for taking the time to post it!
LikeLike
Happy it helps!
LikeLike
[…] time ago I wrote this post about different storage options in Azure Red Hat OpenShift. One of the options discussed was using Azure NetApp Files for […]
LikeLike
[…] Azure Files is a very convenient storage option when you need persistent state in Azure Kubernetes Service or Azure Red Hat OpenShift. It is cheap, it doesn’t count against the maximum number of disks that can be attached to each worker node, and it supports many pods mounting the same share at the same time. The one downside is it’s reduced performance when compared to other options (see my previous post on storage options for Azure Red Hat Openshift). […]
LikeLike