
Azure Route Server is a very powerful tool that thas been recently brought to the Azure Networking toolset: it offers a BGP API so that virtual machines can communicate with a VNet to learn and advertise routes.
I have written some articles about Route Server in the past on how to achieve certain scenarios, but I often get questions about the part of those articles where I come to the need of an encapsulation protocol to fulfill certain connectiviy requirements. Hence this article, where I will touch on some of the most common topologies, and why overlays help to overcome the challenges that will appear.
The purpose of this article is not covering every single scenario with Azure Route Server (I can think of a design with Azure VMware Solution that also requires an overlay, which I don’t cover here), but to give you a mental framework to understand routing problems that may arise when using the Azure Route Server in your designs.
Refresh: How does VNet routing work?
Before we start, it can be useful bringing everybody to the same page, since a wrong understanding of how Azure VNet routing works will make the rest of the article difficult to understand. IT specialists with a background on hardware-based networking often imagine Virtual Networks as having a sort of virtual router inside, where virtual machines are connected to:
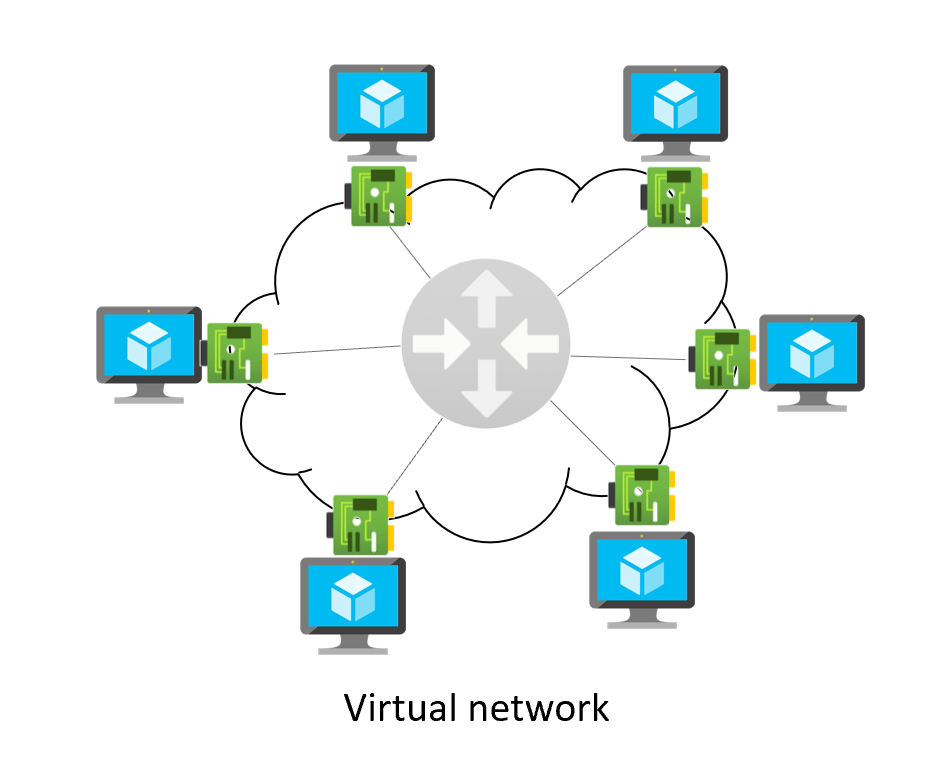
If this is how you picture VNets in your head, you are wrong. Thinking of a VNet in these terms can lead to wrong assumptions, since it is going to be hard fitting concepts like route tables into this model. Instead, it would be more beneficial thinking of a VNet as a set of virtual NICs directly connected to each other with a full-mesh network (Azure SDN), where each NIC performs its own routing functions being a sort of “mini router” in its own right:

Now fitting User Defined Routes (UDRs) and route tables in this model is easier, since those are just static routes that you configure on one or more of those NIC-routers. That is as well the reason why to inspect routing in a VNet you need to show the “effective routes” at the NIC level (not at the VNet or subnet level). For example, every NIC in this basic VNet (without Virtual Network Gateways or peerings, we will get to it later) would show an effective route table like this:

You might notice that subnets are just a groups of NICs, without any other implication whatsoever. Forget about subnets as broadcast domains or layer 2 segments. Subnets happen to be the level at which route tables are configured in Azure, but UDRs are ultimately programmed in NICs.
Bringing Virtual Network Gateways and VNet peering into the picture
Representing VPN or ExpressRoute Virtual Network Gateways (VNGs) and VNet peerings with this model is easy. For example, if we imagine a VNG connected via ExpressRoute or site-to-site VPN to an on-premises network, this is what it would look like (the VNG’s NIC is grayed out, since it is managed by Microsoft and it is not accessible in Azure):
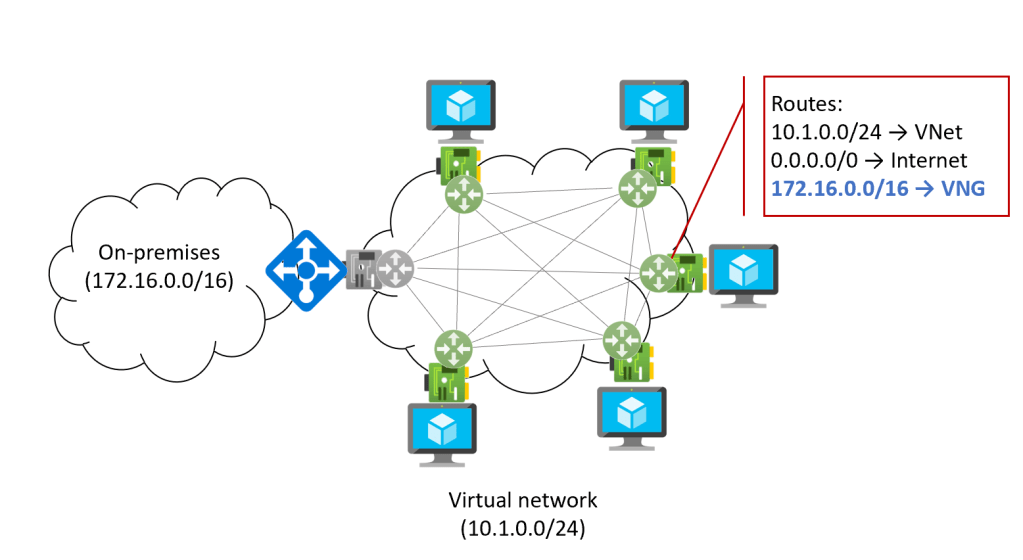
The VNG injects into the effective routes of each NIC the corresponding information, so that each VM knows how to get to the on-premises network, so the effective route table of every NIC in the VNet is now increased with one route.
Note that route tables can be used to prevent VNets from learning routes injected by Virtual Network Gateways, with the setting “Disable Gateway Route Propagation”, however this is an all-or-nothing check, and it affects routes coming from other resources such as Virtual WAN and Azure Route Server too.
Tackling now the VNet peerings, here is a representation of a central VNet (also known as hub) peered to two other VNets (also known as spokes):

As you can see, peering two VNets with each other extends the full-mesh connectivity between their NICs. The previous diagram shows as well why VNet peering is not transitive: VMs in spoke 1 are not fully-meshed to VMs in spoke 2, and hence they cannot communicate directly to each other.
Azure Route Server in the picture
We can finally bring into our model the Azure Route Server, and a Network Virtual Appliance (NVA) that interacts with it via BGP. We can start with a basic design with a single spoke, where the NVA advertises to the route server a 0.0.0.0/0 route:

Alright, there is a lot to unpack in this picture. Let’s start with the spoke VMs: the Azure Route Server behaves in the same way as a VNG, injecting information into the effective routes of each and every NIC. If you look at the effective routes of the VMs in the spoke, there are two routes that have been injected:
- 0.0.0.0/0: injected by the Azure Route Server, who learnt it from the NVA via BGP. This route makes sense, because you want the spoke VMs to send Internet traffic to the NVA
- 172.16.0.0/16: injected by the Virtual Network Gateway (VPN or ExpressRoute). This route will force on-prem traffic to bypass the NVA
What if you wanted to send traffic between the spoke VMs and on-premises through the NVA as well? Of course, you could configure route tables in all of the spoke subnets and override the 172.16.0.0/16 route with an UDR. This option is doable if you have a limited amount of routes, but if you have many routes, this approach quickly becomes a problem.
Overlay from an on-premises router
A possible solution to the problem above might be not advertising the 172.16.0.0/16 over ExpressRoute, but instead creating a tunnel from an on-premises router (in the diagram labeld CPE or Customer Premises Equipment) to the NVA, so that only the NVA knows how to get back home (notice the route that the NVA learns pointing to its tunnel interface). The NVA will then inform everybody else in the VNet. This is what the following diagram illustrates:
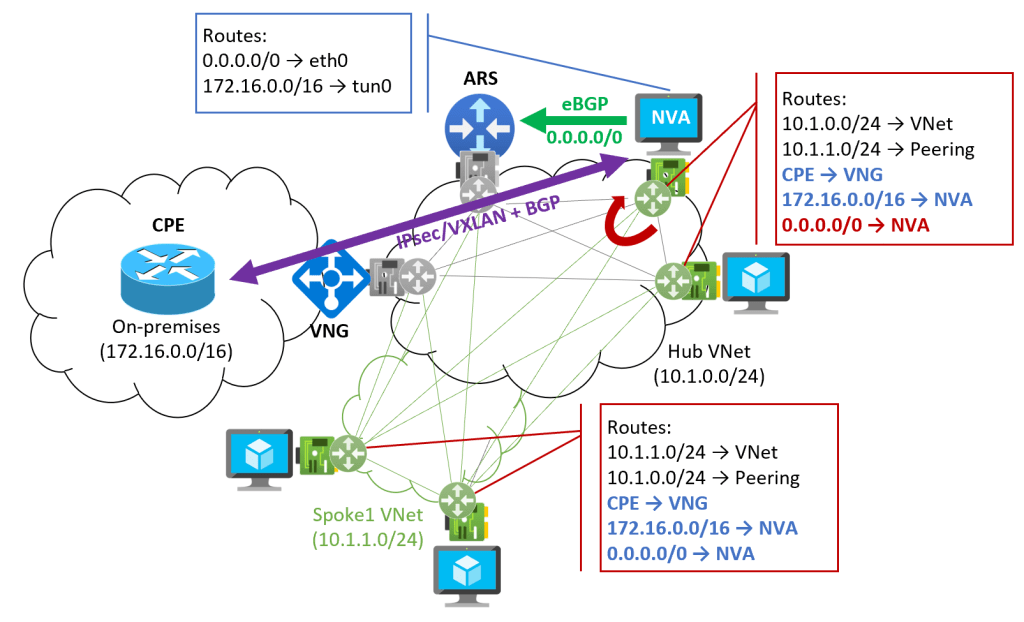
Note that the spoke VMs now learn the on-premises prefix 172.16.0.0/16 from the NVA, and not from the VNG. The only prefix that needs to be learnt over the VNG is the actual IP address of the CPE, so that the overlay tunnel can be established between the CPE and the NVA. Of course, for redundancy reason you would probably have more than one CPE and NVA, and consequently more than one tunnel.
When the NVA sends traffic back to onprem, it will be encapsulated in some kind of overlay protocol such as IPsec or VXLAN (Azure doesn’t support GRE), so the route for 172.16.0.0/16 in its own NIC will not affect this encapsulated traffic.
When sending traffic to the public Internet however there is a problem with the 0.0.0.0/0 route, that the Azure Route Server injected in the NVA NIC (as in each and every other NIC in the VNet), since it creates a routing loop. However, it is easy enough applying a route table to the NVA subnet and override the 0.0.0.0/0 with a UDR with Internet as next hop.
The multi-region routing loop
A similar problem will appear in multiregion designs. Let’s have a look at this sample new design, where two hub VNets, each with its own spoke, are connected to each other:

Here again, looking at the route table in a spoke VM everything looks fine. However, since the Azure Route Server does no distinction between VMs, it will program exactly the same routes in the NVA’s NIC, which will be a problem. Let’s see why.
Imagine that a VM in spoke 1 (left) wants to talk to a VM in spoke 2 (right). The VM will send the packet to NVA1, according to its routing table. NVA1 knows how to reach spoke 2, because NVA2 has advertised it via BGP, so it sends the packet to NVA2. However, NVA1’s NIC has a route for spoke 2 pointing back to NVA1, so it will send the packet back, and create a routing loop.
You might be thinking about disabling Gateway Route Propagation in the NVA’s NIC, but then the route back to on-premises (either the whole 172.16.0.0/16 or the CPE’s IP address if using an overlay from onprem) would be gone. If the connectivity to on-premises is done via S2S VPN, you could restablish that communication with an UDR of next-hop VNG, but if it is ExpressRoute, you are out of luck (UDRs with next-hop VNG do not work for ExpressRoute gateways).
Your next thought might be overriding that 10.2.2.0/24 with an UDR, and this would indeed be a valid solution. You would require an internal Load Balancer in front of each NVA to provide redundancy (assuming you have at least two NVAs in each region), plus you would have to potentially overwrite quite some routes. Depending on the complexity of your scenario, this might or might not be an option.
Overlay between regions
So we end up in a similar solution: creating an overlay between the NVAs in each region, using encapsulation protocols such as IPsec or VXLAN, you can escape this problem, as this diagram shows:
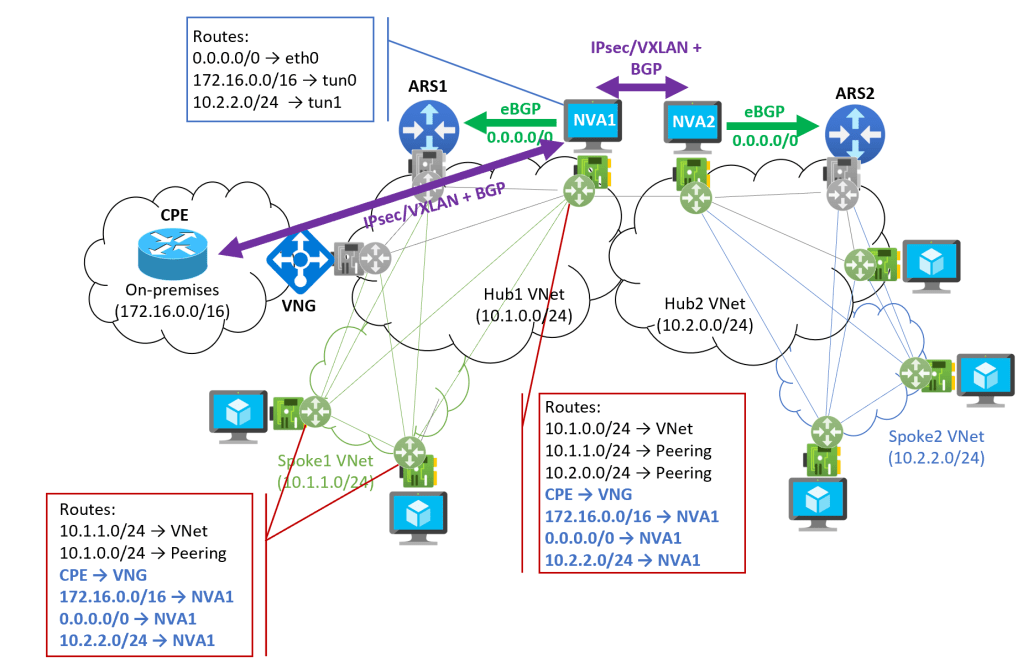
As you can see, the NVAs are sending all egress traffic to on-premises or to other regions via an overlay using encapsulation protocols such as IPsec or VXLAN (hence the routes inside of the NVA using its tunnel interfaces, tun0 and tun1 in this example), so the routes injected by the Azure Route Server are not a problem. Internet traffic is an exemption, but this one can be easily overwritten with a single UDR.
Overlay or UDRs?
In this article I have focused on the overlay option, but in others (for example in Multi-region design with ARS and no overlay) I have explored in depth what the solution with User Defined Routes would look like. All in all, I think the overlay solution is much more flexible and dynamic, although it is true that it requires some extra functionality from the NVA and it raises some questions such as fragmentation and MTU or potential bandwidth limitations of IPsec.
What are your thoughts? Which option do you see better for your environment? Thanks for reading!

Wow this was really cool!
I have an interesting scenario, I have deployed vWAN with multiple vHUBs, an Express route for onPrem DC and a bunch of site-to-site VPNs for branches. I’m trying to convert a vHUB into a secure hub, but there’s an issue when trying to protect private traffic rfc1918. Express Route is advertising more spefici routes so all the VNET VMs[now that I know how this works, VM NICs] learn these more speficif routes via ExpressRoute and completely bypass the AzureFirewall.
Can you maybe cover some vWAN stuff, secured vhubs etc?
LikeLike
Thanks for your comment Ed, happy this was useful! What aspect of Virtual WAN would you like to see highlighted? One idea in my head is to double click on the indirect spoke model which I touched upon in https://blog.cloudtrooper.net/2022/01/18/is-the-core-distribution-access-design-dead/. Would that help?
LikeLike
That was very enlightening, thanks. The idea of ARS as a routing orchestartor seems very attractive; however the fact that ARS installs the prefixes learned from NVA back into its NIC, and thus creating a routing loop, is utterly disappointing. The solution you’ve proposed with a tunnel overlay is witty but having the on-prem to vnet traffic double-encapsulated in IPSec ESP (s2s vng)… not that good. Pls, consider the following alternative (with respect to your diagram ‘VNet model with VNG, VNet peering and ARS’) : create _two_ UDR’s on NVA – 172.16.0.0/17 and 172.16.128.0/17 (next-hop=VNG) and annouce both via BGP to ARS. The latter will program these more specific routes on VM’s. Do you think it’ll work as expected? Thanks again, alex.
LikeLike
In the first central hub scenario, I think there is an issue with Spoke2. It should be 10.1.1.0/24 -> Peering and/or 10.1.2.0/24 -> VNET shouldn’t it ?
Thank you so much for all your articles. Just super useful ! Always clear and understandable.
LikeLike
Yes there is an error, thx! Effective routes in spoke2 should be 10.1.2.0/24->VNet (local prefix) and 10.1.0.0/24->Peering (hub). I will try to fix it tomorrow, good catch!
LikeLike
Alright, I finally found time to fix the image, now it should be correct
LikeLike
Hi,
Thank you for such a great article !! I’ve got a question regarding the VPN tunnels on the NVAs. Are they just meant for BGP traffic or also data traffic ? I’m a bit struggling to implement a multiregion scenario with a pair of NVAs on each regions + an ARS. Hub vnets linked with a global peering. The NVA to NVA tunnel is my pain point actually and I would like some clarifications about it.
LikeLike
Happy it helps! The tunnels are mainly meant for data traffic, to avoid the requirement that Azure is able to route the packets correctly (the encapsulation obfuscates the original headers from Azure).
LikeLike
Thanks for your answer ! So the VPN Gateway and the global peering is no more need and you just use the NVA to handle the tunnels ?
LikeLike
Forget my last comment the tunnel is on top of the global peering so it’s still needed
LikeLiked by 1 person
Yeah exactly. If using IPsec as encap you dont need the VNet peering, but you are constrained on bandwidth. If you instead use VXLAN, you probably dont want to send that traffic over the public Internet.
LikeLike
Great Article! I have an NVA announcing a subnet to RS and then to VNG. What i saw (same as you write) is that this subnet is also announced back to NVA VNET and then to NVA NIC card, which is something not really nice.
To let the NIC not consider it you then need to add an UDR on top. It should be a mechaninsm to discard those routes. Would be a way to filter out routes (ie prefix listes or routmaps) within Azure avoid this ?
LikeLike
Hey ArcSte! No, unfortunately there isn’t, and that is something built into Azure SDN: a NIC will either take the routes from all the gateways (ER, VPN, ARS) or from none of them. I have been asking for this feature for a while now, believe me.
What you can do however is this design that we recently documented, what I call the “split ARS” scenario: https://docs.microsoft.com/azure/route-server/route-injection-in-spokes#different-route-servers-to-advertise-routes-to-virtual-network-gateways-and-to-vnets. In essence you have one ARS to talk to the gateways, and another one to talk to the spokes.
Does that help?
LikeLike
[…] have to be overridden by UDRs (or use some encapsulation between the NVAs in different regions, see this post for more details). We will see this overriding later in this […]
LikeLike
[…] I have already discussed about this in the past. This picture might look familiar as a representation of a VNet, if you have read this post: […]
LikeLike