
This post is a continuation from Part 4: NSGs. Other posts in this series:
- Part 1: deep dive in AKS with Azure CNI in your own vnet
- Part 2: deep dive in AKS with kubenet in your own vnet, and ingress controllers
- Part 3: outbound connectivity from AKS pods
- Part 4: NSGs with Azure CNI clusters
- Part 5 (this one): Virtual Node
- Part 6: Network Policy with Azure CNI
Virtual Node
In Part 4 we have deployed some pods with a LoadBalancer service, and we had a look at the NSG associated to the AKS nodes, so we have restricted inbound communication to the cluster to data traffic, so we know that all control plane flows are outgoing.
Let us focus now on the virtual node. In Part 4 we deployed the virtual node extension, let us see what this did:
$ k get node -o wide NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME aks-nodepool1-26711606-0 Ready agent 86m v1.12.5 10.13.76.4 <none> Ubuntu 16.04.5 LTS 4.15.0-1037-azure docker://3.0.4 virtual-node-aci-linux Ready agent 65m v1.13.1-vk-v0.7.4-44-g4f3bd20e-dev 10.13.76.13 <none> <unknown> <unknown> <unknown>
Now we have a second node, with an IP coming from our main AKS subnet. Wait a second, this seems to collide with the IP address range assign for pods in node 0, right? (see the Part 1 of this blog series for a deep dive on Azure CNI pod/node addressing). That is because the virtual node is represented by a pod inside of one of the nodes:
$ k get pod -n kube-system -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE aci-connector-linux-7775fbcf5f-mhrjs 1/1 Running 1 67m 10.13.76.13 aks-nodepool1-26711606-0 <none> ...
Note that we have this aci-connector pod running in our node, that has the same IP as we saw in the virtual node before.
Sweet! Let’s check the taints of our nodes:
$ k describe node/aks-nodepool1-26711606-0 | grep Taints Taints: <none> $ k describe node/virtual-node-aci-linux | grep Taints Taints: virtual-kubelet.io/provider=azure:NoSchedule
As you can see, the virtual node is tainted. Hence the toleration in our deployment manifest above.
tolerations:
- key: virtual-kubelet.io/provider
operator: Exists
- effect: NoSchedule
key: azure.com/aci
In order to prefer the virtual machines rather than the virtual nodes, I configured an affinity rule:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: type
operator: NotIn
values:
- virtual-kubelet
This is matching on a label assigned to the virtual node:
$ k describe node/virtual-node-aci-linux | grep type
type=virtual-kubelet
Our deployment is spread over both nodes (the VM and the virtual node):
$ k get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE kuard-vnode-bd88cbf77-czqvs 1/1 Running 0 13m 10.13.76.11 aks-nodepool1-26711606-0 <none> kuard-vnode-bd88cbf77-rw8rv 1/1 Running 0 13m 10.13.100.4 virtual-node-aci-linux <none>
Note how the IP address of the pod in the virtual node is in a different subnet, which is the one we configured for the virtual-node addon. If you check the deployed Azure Container Instances, there should be one there:
$ az container list -o table Name ResourceGroup Status Image CPU/Memory OsType Location IP:ports Network ----------------------------------- ------------------------------------- --------- --------------------------------------- --------------- -------- ---------- --------------------- --------- default-kuard-vnode-bd88cbf77-rw8rv MC_akstest_azurecnicluster_westeurope Succeeded gcr.io/kuar-demo/kuard-amd64:blue 0.5 core/1.5 gb Linux westeurope 10.13.100.4:8080,8080 Private
Note that the resources reserved for the Azure Container Instance are the same ones as specified in the yaml manifest.
Let’s keep on diving. Let us have a look at the loadbalancer deployed in Azure. More specifically, at the backend address pool:
$ lbname=$(az network lb list -g $noderg_azure --query [0].name -o tsv)
$ poolname=$(az network lb address-pool list -g $noderg_azure --lb-name $lbname --query [0].name -o tsv)
$ az network lb address-pool show -g $noderg_azure --lb-name $lbname -n $poolname --query backendIpConfigurations
[
{
"applicationGatewayBackendAddressPools": null,
"applicationSecurityGroups": null,
"etag": null,
"id": "/subscriptions/e7da9914-9b05-4891-893c-546cb7b0422e/resourceGroups/MC_akstest_azurecnicluster_westeurope/providers/Microsoft.Network/networkInterfaces/aks-nodepool1-26711606-nic-0/ipConfigurations/ipconfig1",
"loadBalancerBackendAddressPools": null,
"loadBalancerInboundNatRules": null,
"name": null,
"primary": null,
"privateIpAddress": null,
"privateIpAddressVersion": null,
"privateIpAllocationMethod": null,
"provisioningState": null,
"publicIpAddress": null,
"resourceGroup": "MC_akstest_azurecnicluster_westeurope",
"subnet": null,
"virtualNetworkTaps": null
}
]
As you can see, only one IP configuration exists in the backend pool. In other words, Azure Load Balancer will send all traffic through our single node, that will then load balance to either its local pods, or the pods in Azure Container Instances.
As we did in previous posts, let’s have a look at its IPtables configuration. I happen to have a jump host in the same Vnet with the public IP address 23.97.131.191 and the same public SSH keys, so I will go over it to connect to the AKS node using the “ssh -J” command:
$ ssh -J 23.97.131.191 10.13.76.4 [...] jose@aks-nodepool1-26711606-0:~$ sudo iptables-save | grep kuard -A KUBE-FW-AXSEUH3JK6RISVJZ -m comment --comment "default/kuard-vnode: loadbalancer IP" -j KUBE-MARK-MASQ -A KUBE-FW-AXSEUH3JK6RISVJZ -m comment --comment "default/kuard-vnode: loadbalancer IP" -j KUBE-SVC-AXSEUH3JK6RISVJZ -A KUBE-FW-AXSEUH3JK6RISVJZ -m comment --comment "default/kuard-vnode: loadbalancer IP" -j KUBE-MARK-DROP -A KUBE-NODEPORTS -p tcp -m comment --comment "default/kuard-vnode:" -m tcp --dport 30610 -j KUBE-MARK-MASQ -A KUBE-NODEPORTS -p tcp -m comment --comment "default/kuard-vnode:" -m tcp --dport 30610 -j KUBE-SVC-AXSEUH3JK6RISVJZ -A KUBE-SERVICES ! -s 10.13.76.0/24 -d 10.0.236.245/32 -p tcp -m comment --comment "default/kuard-vnode: cluster IP" -m tcp --dport 8080 -j KUBE-MARK-MASQ -A KUBE-SERVICES -d 10.0.236.245/32 -p tcp -m comment --comment "default/kuard-vnode: cluster IP" -m tcp --dport 8080 -j KUBE-SVC-AXSEUH3JK6RISVJZ -A KUBE-SERVICES -d 13.80.27.137/32 -p tcp -m comment --comment "default/kuard-vnode: loadbalancer IP" -m tcp --dport 8080 -j KUBE-FW-AXSEUH3JK6RISVJZ
Let’s break this down: First, the LB rule will hit the public IP address (remember that the “IP floating” option is turned on in the LB rule, as we saw in Part 1 of the blog series):
-A KUBE-SERVICES -d 13.80.27.137/32 -p tcp -m comment --comment "default/kuard-vnode: loadbalancer IP" -m tcp --dport 8080 -j KUBE-FW-AXSEUH3JK6RISVJZ
This rule forwards packets to the next chain, “KUBE-FW-AXSEUH3JK6RISVJZ”. This chain has three rules:
-A KUBE-FW-AXSEUH3JK6RISVJZ -m comment --comment "default/kuard-vnode: loadbalancer IP" -j KUBE-MARK-MASQ -A KUBE-FW-AXSEUH3JK6RISVJZ -m comment --comment "default/kuard-vnode: loadbalancer IP" -j KUBE-SVC-AXSEUH3JK6RISVJZ -A KUBE-FW-AXSEUH3JK6RISVJZ -m comment --comment "default/kuard-vnode: loadbalancer IP" -j KUBE-MARK-DROP
- The first rule in this chain marks the packet for source NAT (also known as masquerading in iptables parlance): as a consequence, the pod will not see the original client IP address
- The second sends it to the iptables chain responsible for handling the load balancing inside of the cluster
- If it came to the third rule, traffic would be dropped
Let’s see that masquerading NAT rule:
jose@aks-nodepool1-26711606-0:~$ sudo iptables-save | grep '\-A KUBE-MARK-MASQ' -A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000
This marks traffic internally setting the second bit of the first byte. The KUBE-POSTROUTING chain will eventually source NAT packets with that mark:
jose@aks-nodepool1-26711606-0:~$ sudo iptables-save | grep '\-A KUBE-POSTROUTING' -A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -m mark --mark 0x4000/0x4000 -j MASQUERADE
As we saw in Part 1 of this blog series, marking a packet is a ‘non-terminating’ rule in iptables. That means that further rules in the chain are processed, so we move on to the next rule, the rule, “KUBE-SVC-AXSEUH3JK6RISVJZ”. We did not catch this chain with our previous command:
jose@aks-nodepool1-26711606-0:~$ sudo iptables-save | grep '\-A KUBE-SVC-AXSEUH3JK6RISVJZ' -A KUBE-SVC-AXSEUH3JK6RISVJZ -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-PFDO2KGI5VXHCUTC -A KUBE-SVC-AXSEUH3JK6RISVJZ -j KUBE-SEP-DSPMX7OQIPXIOG5Z
These are the endpoint rules: the first one sends 50% of the traffic to chain “KUBE-SEP-PFDO2KGI5VXHCUTC”, and the remaining traffic goes to “KUBE-SEP-DSPMX7OQIPXIOG5Z”. Here the one for the first endpoint:
jose@aks-nodepool1-26711606-0:~$ sudo iptables-save | grep '\-A KUBE-SEP-PFDO2KGI5VXHCUTC' -A KUBE-SEP-PFDO2KGI5VXHCUTC -s 10.13.100.4/32 -j KUBE-MARK-MASQ -A KUBE-SEP-PFDO2KGI5VXHCUTC -p tcp -m tcp -j DNAT --to-destination 10.13.100.4:8080
When outbound traffic is coming from the ACI pod (IP address 10.13.100.4) it marks it for source NAT. For traffic going to the ACI pod, changes the destination IP address (at this point still the public IP) to the private IP of the pod.
And similarly, here the second one:
jose@aks-nodepool1-26711606-0:~$ sudo iptables-save | grep '\-A KUBE-SEP-DSPMX7OQIPXIOG5Z' -A KUBE-SEP-DSPMX7OQIPXIOG5Z -s 10.13.76.11/32 -j KUBE-MARK-MASQ -A KUBE-SEP-DSPMX7OQIPXIOG5Z -p tcp -m tcp -j DNAT --to-destination 10.13.76.11:8080
Adding up, for ingress traffic:
- Traffic is marked for source NAT
- iptables load balances 50% of the traffic to each endpoint
- For each endpoing, DNAT sets the correct destination IP
- The KUBE-POSTROUTING chain does the source NAT
Let us now testing some connectivity:

As you can see in the picture, the page was served from 10.13.100.4, that is, the pod running as Azure Container Instance. Let us see the NAT table in the node for connections sourced from our public IP address:
jose@aks-nodepool1-26711606-0:~$ sudo conntrack -L -s 109.125.121.169 tcp 6 264 ESTABLISHED src=109.125.121.169 dst=13.80.27.137 sport=59337 dport=8080 src=10.13.100.4 dst=10.13.76.4 sport=8080 dport=59337 [ASSURED] mark=0 use=1 conntrack v1.4.3 (conntrack-tools): 1 flow entries have been shown.
These are the four IP addresses in the conntrack output:
- 109.125.121.169: client-side source IP (before NAT)
- 13.80.27.137: client-side destination IP (before NAT). You can see this IP address in the HTTP Host header in the screenshot above
- 10.13.100.4: pod-side destination IP (it is showed as “src” because it represents the return traffic). You can see this IP address in the “Serving on” section of the screenshot above, it is the IP address of the pod itself
- 10.13.76.4: pod-side source IP (and in the conntrack output as “dst”, since it is going to be the destination for return traffic). You can see this address in the “Client address” field of the screenshot above, this is the IP address that will appear in the HTTP logs as source IP.
As a summary, we have seen that Azure Load Balancer sends the traffic to the VM-based nodes (not to the virtual node). Via NAT rules, the iptables configuration in the node will load balance traffic across all endpoints in the service.
Virtual Node with Ingress Controller
How does all this look like if there is an ingress controller in front of the nodes? As per previous posts, this is what we would expect:
- The ingress controller nginx pods will be addressed by the Azure Load Balancer
- The ingress controller pods will establish connectivity to the individual pods using the ClusterIP service.
Let us verify this. As preparation, I have added the HTTP Application Routing to the cluster, and I have deployed another set of pods with ingress rules in a different namespace:
$ az aks enable-addons -a http_application_routing -g $rg -n $aksname_azure $ k create ns ingress namespace/ingress created $ k apply -f ./kuard-vnode-ingress.yaml deployment.apps/kuard-vnode created service/kuard-vnode created ingress.extensions/whereami-ingress created $ k -n ingress get ingress NAME HOSTS ADDRESS PORTS AGE whereami-ingress kuard-ingress.caeb951f8b49453dbc84.westeurope.aksapp.io 23.97.235.37 80 151m
Now we can test access through the ingress controller:
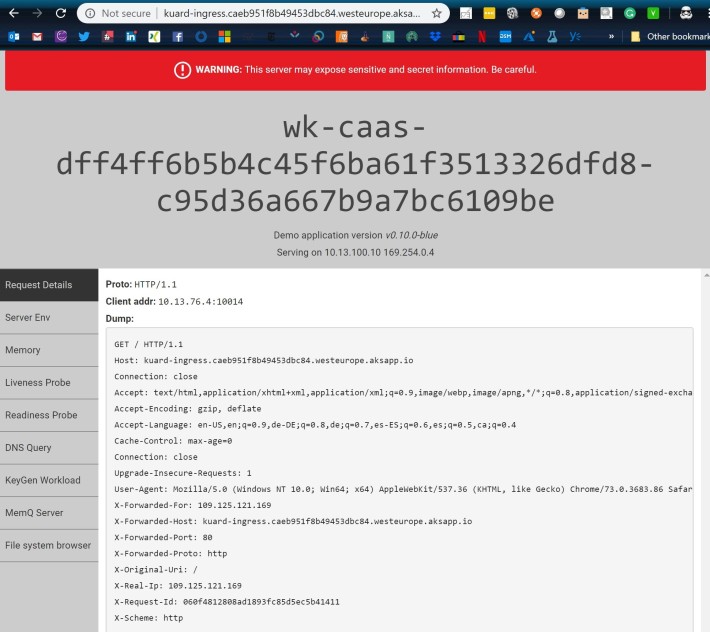
As you can see in the Host header, the client is accessing the URL specified by the ingress. Something interesting is that the client address is 10.13.76.4. This is the IP address of the node itself, but not the IP address of the ingress pods. In other words, the nginx ingress controller is not accessing the pods directly, but through the ClusterIP service.
Let’s inspect the connection table. First, the NAT entries for the TCP connection to the nginx frontends:
jose@aks-nodepool1-26711606-0:~$ sudo conntrack -L -d 23.97.235.37 tcp 6 116 TIME_WAIT src=130.61.110.138 dst=23.97.235.37 sport=48600 dport=443 src=10.13.76.17 dst=130.61.110.138 sport=443 dport=48600 [ASSURED] mark=0 use=1 conntrack v1.4.3 (conntrack-tools): 1 flow entries have been shown.
We can confirm that 10.13.76.17 is actually the IP address of the nginx controller:
$ k -n kube-system get pod -o wide | grep nginx addon-http-application-routing-nginx-ingress-controller-8fx6v2r 1/1 Running 0 176m 10.13.76.17 aks-nodepool1-26711606-0 <none>
And now, the ingress controller will establish the connection to the individual pods:
jose@aks-nodepool1-26711606-0:~$ sudo conntrack -L -s 10.13.76.17 tcp 6 86399 ESTABLISHED src=10.13.76.17 dst=40.118.18.202 sport=59574 dport=443 src=40.118.18.202 dst=10.13.76.4 sport=443 dport=60009 [ASSURED] mark=0 use=1 tcp 6 117 TIME_WAIT src=10.13.76.17 dst=10.13.100.10 sport=59850 dport=8080 src=10.13.100.10 dst=10.13.76.4 sport=8080 dport=10014 [ASSURED] mark=0 use=1 conntrack v1.4.3 (conntrack-tools): 2 flow entries have been shown.
The first connection is not something that we need be concerned about, however let us look quickly into it. This is outbound communication that the nginx ingress controller runs for calls to the kubernetes API in the master nodes:
$ k cluster-info Kubernetes master is running at https://azurecnicl-akstest-e7da99-2b574e43.hcp.westeurope.azmk8s.io:443 [...] $ nslookup azurecnicl-akstest-e7da99-2b574e43.hcp.westeurope.azmk8s.io Server: 195.234.128.139 Address: 195.234.128.139#53 Non-authoritative answer: Name: azurecnicl-akstest-e7da99-2b574e43.hcp.westeurope.azmk8s.io Address: 40.118.18.202
The second conntrack entry is more interesting: we see that the client-side destination IP address is the IP address of the pod in the virtual node subnet (10.13.100.10). We see as well in the pod-side address that the ingress controller will be source-NATted to 10.13.76.4, port 10014. You can actually see this IP address and port in the screenshot above, under “Client addr”.
This is interesting: pod-to-pod communication seems to be source-NATted as well. Let us verify it: we will connect to the console of the nginx pod, and do two requests: one to a pod on a VM, another one to a pod on an Azure Container Instance:
$ k -n kube-system exec -it addon-http-application-routing-nginx-ingress-controller-8fx6v2r -- /bin/bash www-data@addon-http-application-routing-nginx-ingress-controller-8fx6v2r:/etc/nginx$ curl -s4 10.13.100.10:8080 | grep requestAddr [...]"requestAddr":"10.13.76.4:29425"} www-data@addon-http-application-routing-nginx-ingress-controller-8fx6v2r:/etc/nginx$ curl -s4 10.13.76.11:8080 | grep requestAddr [...]"requestAddr":"10.13.76.17:39958"}
As you can see, when the ingress controller connects to 10.13.100.10 (a pod on an ACI), the source address that the pod sees is the node address. Note the difference when connecting to a pod in the same node.
What if the pod were in a different node? We need to add a new node to our cluster to test this:
$ az aks scale -g $rg -n $aksname_azure -c 2 --no-wait
After deleting the pod in node 0, it should be recreated in node 1 (since node 1 is free, and our node affinity rules will prefer VMs to the virtual node):
$ k get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE kuard-vnode-bd88cbf77-czqvs 1/1 Running 0 16h 10.13.76.11 aks-nodepool1-26711606-0 <none> kuard-vnode-bd88cbf77-g58q7 1/1 Running 0 108m 10.13.100.6 virtual-node-aci-linux <none> $ k delete pod/kuard-vnode-bd88cbf77-czqvs pod "kuard-vnode-bd88cbf77-czqvs" deleted $ k get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE kuard-vnode-bd88cbf77-g58q7 1/1 Running 0 111m 10.13.100.6 virtual-node-aci-linux <none> kuard-vnode-bd88cbf77-n8dzg 1/1 Running 0 2m46s 10.13.76.36 aks-nodepool1-26711606-1 <none>
We can have a look again at the source IP address that the nginx pod will see:
$ k -n kube-system exec -it addon-http-application-routing-nginx-ingress-controller-8fx6v2r -- /bin/bash www-data@addon-http-application-routing-nginx-ingress-controller-8fx6v2r:/etc/nginx$ curl -s4 10.13.100.6:8080 | grep requestAddr [...]"requestAddr":"10.13.76.4:32320"} www-data@addon-http-application-routing-nginx-ingress-controller-8fx6v2r:/etc/nginx$ curl -s4 10.13.76.36:8080 | grep requestAddr [...]"requestAddr":"10.13.76.17:52820"}
Alright, it is confirmed: when a pod (in this example nginx, running in node 0 with IP 10.13.76.17) accesses a pod running on the virtual node (in this example 10.13.100.6), its IP address gets NATted. For access to pods running in VMs (in this example 10.13.76.36) its address is NOT translated, independently of whether they run in the same node or in a different node.
Now, let’s have a look at our iptables friends from the node perspective. We can start with the rules responsible for our kuard-vnode-ingress service:
jose@aks-nodepool1-26711606-0:~$ sudo iptables-save | grep kuard-vnode-ingress -A KUBE-SERVICES ! -s 10.13.76.0/24 -d 10.0.230.28/32 -p tcp -m comment --comment "ingress/kuard-vnode-ingress: cluster IP" -m tcp --dport 8080 -j KUBE-MARK-MASQ -A KUBE-SERVICES -d 10.0.230.28/32 -p tcp -m comment --comment "ingress/kuard-vnode-ingress: cluster IP" -m tcp --dport 8080 -j KUBE-SVC-4RGWI3S4SEKPJ55Y
The first rule is to source NAT anything going from the cluster to the ClusterIP (10.0.230.28:8080), and the second jumps to the endpoint chain “KUBE-SVC-4RGWI3S4SEKPJ55Y”. Let’s peek into it:
jose@aks-nodepool1-26711606-0:~$ sudo iptables-save | grep "\-A KUBE-SVC-4RGWI3S4SEKPJ55Y" -A KUBE-SVC-4RGWI3S4SEKPJ55Y -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-FDOYREXGM5TS33NA -A KUBE-SVC-4RGWI3S4SEKPJ55Y -j KUBE-SEP-EL4VZO2BNEWOSUMB
And in each of the endpoint chains you find the NAT rule for the return traffic, plus the DNAT rule for the traffic to the endpoint (in this order). For example, here the rule going to one of the pods in the virtual node:
jose@aks-nodepool1-26711606-0:~$ sudo iptables-save | grep "\-A KUBE-SEP-FDOYREXGM5TS33NA" -A KUBE-SEP-FDOYREXGM5TS33NA -s 10.13.100.4/32 -j KUBE-MARK-MASQ -A KUBE-SEP-FDOYREXGM5TS33NA -p tcp -m tcp -j DNAT --to-destination 10.13.100.4:8080
But that does not explain why outbound traffic to the virtual node subet is NATted. Source NAT in iptables is controlled by the POSTROUTING chain in the NAT table. Let’s have a look at it:
jose@aks-nodepool1-26711606-0:~$ sudo iptables -t nat --list-rule POSTROUTING -P POSTROUTING ACCEPT -A POSTROUTING -m comment --comment "cali:O3lYWMrLQYEMJtB5" -j cali-POSTROUTING -A POSTROUTING -m comment --comment "kubernetes postrouting rules" -j KUBE-POSTROUTING -A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE -A POSTROUTING -m comment --comment "ip-masq-agent: ensure nat POSTROUTING directs all non-LOCAL destination traffic to our custom IP-MASQ-AGENT chain" -m addrtype ! --dst-type LOCAL -j IP-MASQ-AGENT
Out of these routes we will look first at the kubernetes postrouting rules, which is jumping to the chain KUBE-POSTROUTING, which we already know from before:
jose@aks-nodepool1-26711606-0:~$ sudo iptables -t nat --list-rule KUBE-POSTROUTING -N KUBE-POSTROUTING -A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -m mark --mark 0x4000/0x4000 -j MASQUERADE
Let’s assume that nobody has marked our packet with 0x4000 yet. The last rule of the POSTROUTING chain seems interesting. Let’s go into the chain IP-MASQ-AGENT:
jose@aks-nodepool1-26711606-0:~$ sudo iptables -t nat --list-rule IP-MASQ-AGENT -N IP-MASQ-AGENT -A IP-MASQ-AGENT -d 10.13.0.0/16 -m comment --comment "ip-masq-agent: cluster-local traffic should not be subject to MASQUERADE" -m addrtype ! --dst-type LOCAL -j RETURN -A IP-MASQ-AGENT -d 168.63.129.16/32 -m comment --comment "ip-masq-agent: cluster-local traffic should not be subject to MASQUERADE" -m addrtype ! --dst-type LOCAL -j RETURN -A IP-MASQ-AGENT -m comment --comment "ip-masq-agent: outbound traffic should be subject to MASQUERADE (this match must come after cluster-local CIDR matches)" -m addrtype ! --dst-type LOCAL -j MASQUERADE
Interesting. The first rule should match on 10.13.0.0/16, which actually includes our IP range for pods in the virtual node. By the way, these ranges are defined in the configuration map of the IP masq agent:
$ k -n kube-system describe cm/azure-ip-masq-agent-config [...] Data ==== ip-masq-agent: ---- nonMasqueradeCIDRs: - 10.13.0.0/16 - 168.63.129.16/32 masqLinkLocal: true resyncInterval: 60s Events: <none>
So if it is not the IP masquerade agent, does that mean that somebody is marking our packets with 0x4000 in the “filter” table? That would mean that packets are being sent to the chain KUBE-MARK-MASQ? Or that some other rule is matching on 10.13.76.0/24 but not on 10.13.0.0/16?
Hint:
jose@aks-nodepool1-26711606-0:~$ sudo ipset list cali40all-ipam-pools Name: cali40all-ipam-pools Type: hash:net Revision: 6 Header: family inet hashsize 1024 maxelem 1048576 Size in memory: 408 References: 1 Number of entries: 1 Members: 10.13.76.0/24
Connectivity from a pod on a virtual node
But if connectivity from the nginx pod to the kuard pod on ACI works using the iptables rules in the VM where the source pod (nginx) is, how would that work the other way round? For example, how would a pod on ACI reach a ClusterIP service?
Let us connect to one of the pods on a VM and have a look at its routing table:
$ k get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE kuard-vnode-bd88cbf77-g58q7 1/1 Running 0 9h 10.13.100.6 virtual-node-aci-linux <none> kuard-vnode-bd88cbf77-n8dzg 1/1 Running 0 7h35m 10.13.76.36 aks-nodepool1-26711606-1 <none> $ k exec -it kuard-vnode-bd88cbf77-n8dzg -- /bin/ash ~ $ ip route default via 169.254.1.1 dev eth0 169.254.1.1 dev eth0 scope link
Let’s compare it with a pod running on the virtual node:
$ k get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE kuard-vnode-bd88cbf77-g58q7 1/1 Running 0 9h 10.13.100.6 virtual-node-aci-linux <none> kuard-vnode-bd88cbf77-n8dzg 1/1 Running 0 7h34m 10.13.76.36 aks-nodepool1-26711606-1 <none> $ k exec -it kuard-vnode-bd88cbf77-g58q7 -- /bin/ash ~ $ ~ $ ip route default via 169.254.0.1 dev eth1 10.0.0.0/8 via 10.13.100.1 dev eth0 10.13.100.0/24 dev eth0 scope link src 10.13.100.6 169.254.0.0/16 dev eth1 scope link src 169.254.0.4 172.16.0.0/12 via 10.13.100.1 dev eth0 192.168.0.0/16 via 10.13.100.1 dev eth0
Wow, it looks like the routing table in our ACI pod is much more complicated! For a start, there seem to be two network interfaces, eth0 and eth1. Let’s have a look:
~ $ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
9: eth0@if10: <BROADCAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UP qlen 1000
link/ether 0a:d1:37:78:8b:53 brd ff:ff:ff:ff:ff:ff
inet 10.13.100.6/24 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::8d1:37ff:fe78:8b53/64 scope link
valid_lft forever preferred_lft forever
11: eth1@if12: <BROADCAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UP qlen 1000
link/ether de:50:f4:4c:a8:9e brd ff:ff:ff:ff:ff:ff
inet 169.254.0.4/16 scope global eth1
valid_lft forever preferred_lft forever
inet6 fe80::dc50:f4ff:fe4c:a89e/64 scope link
valid_lft forever preferred_lft forever
As you can see, the second interface – eth1 – has a link local IPv4 address (see RFC 3927 for more info).
Let’s analyze the routing table:
- The default gateway is 169.254.0.1 through eth1!
- There are a couple of routes pointing to eth0: obviously 10.13.76.0/24, plus all RFC 1918 private space, which would possibly include the IP address space of the cluster Vnet. Only “possibly”, because in theory you can use public IP address space outside of RFC 1918 in your Azure Vnet.
But where is our default gateway, 169.254.0.1? Where is eth1 going? Frankly, I have no idea. I started trying to reverse engineer this, but given the limited visibility inside of the virtual-node container pod, I decided to stop here.
One question stays in my head though: would the pod in the ACI container be able to reach a ClusterIP service? Let us try:
$ k -n ingress get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kuard-vnode-ingress ClusterIP 10.0.230.28 <none> 8080/TCP 20h $ k -n ingress get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE kuard-vnode-ingress-84d8c9586f-5kf2p 1/1 Running 0 4m27s 10.13.76.52 aks-nodepool1-26711606-1 <none> kuard-vnode-ingress-84d8c9586f-fskj6 1/1 Running 0 3m1s 10.13.100.6 virtual-node-aci-linux <none> $ k -n ingress exec -it kuard-vnode-ingress-84d8c9586f-fskj6 -- /bin/ash ~ $ cd /tmp /tmp $ wget http://10.0.230.28:8080 Connecting to 10.0.230.28:8080 (10.0.230.28:8080) index.html 100% |************************************************************************************************************************************************************************************************| 1549 0:00:00 ETA /tmp $ head index.html <!doctype html> [...]
Here I am using wget, since the kuard image does not have any curl installed. However, as you can see connectivity to the ClusterIP service works just fine. I am planning to investigate how this is actually working

[…] Part 5: Virtual Node […]
LikeLike
[…] Part 5: Virtual Node […]
LikeLike
[…] Part 5: Virtual Node […]
LikeLike
[…] Part 5: Virtual Node […]
LikeLike
[…] post is a continuation from Part 5: Virtual Node. Other posts in this […]
LikeLike